python学习笔记
1.注释与缩进
1.1 注释
以 # 开头,一直到行尾。
1.2 缩进规则
python中,具有相同缩进的代码被视为代码块。
Python的习惯写法:4个空格,不使用Tab,更不要混合Tab和空格,否则很容易造成因为缩进引起的语法错误。
2.数据类型
2.1 整型
16 进制 用 0x 作为前缀。
过大数据可用 e 代表 10 的次方,如 1e3 代表 1000 。
2.2 浮点型
依然可用 e 代表 10 的次方,如 1e-3 代表 0.001 。
2.3 字符串
以' '、" "或''' '''括起来的任意文本。若使用多行文字,用''' '''。
print 'hello\nworld'
print '''hello
world'''
hello
world
hello
world
2.3.1 内部使用'和"
若 想要在字符串内部加上这些符号,可这样用:
print "'hello'"
print '"hello"'
'hello'
"hello"
即,若字符串内部包含',那我们用""括起字符串,若字符串内部包含",那我们用''括起字符串。
若既有'又有"呢?可以使用\转义。
或者最外面使用''',如:
py print '''"hello" 'world' '''
"hello" 'world'
2.3.2 转义
字符串的转义主要是用\和r'...'。
\和 c/c++ 的用法一样,可使用\n等。
r'...'是将''内部分一串都转义,但是不能在内部包含'或".
print r'\\\hhh'
\\hhh
若要包含'或",可用r'''...'''。
print r'''he said, "hi".'''
he said, "hi".
2.3.3 字符串拼接
可使用 + 连接字符串,如:
py print 'hello' + ' ' + 'world'
hello world
(不可将字符串与其他类型用 + 连接)
或者使用 ,会自动加一个空格(逗号自动被替换为空格):
py print 'hello', 'world'
hello world
2.3.4 中文字符
在 python 中,中文字符支持 Unicode 编码,因此,输出中文字符串时,需在前面加u(我的不需要加,可能和python版本之类的有关)。
如果中文字符串在Python环境下遇到 UnicodeDecodeError,这是因为.py文件保存的格式有问题。可以在第一行添加注释
# -*- coding: utf-8 -*-
目的是告诉Python解释器,用UTF-8编码读取源代码。然后用Notepad++ 另存为... 并选择UTF-8格式保存。
2.4 布尔值
2.4.1 基本概念
True 和 False(首字母大写)。
可对布尔值进行 and、or、not运算。
Python把0、空字符串''和None看成 False,其他数值和非空字符串都看成 True。
2.4.2 短路运算
-
在计算 a and b 时,如果 a 是 False,则根据与运算法则,整个结果必定为 False,因此返回 a;如果 a 是 True,则整个计算结果必定取决与 b,因此返回 b。
-
在计算 a or b 时,如果 a 是 True,则根据或运算法则,整个计算结果必定为 True,因此返回 a;如果 a 是 False,则整个计算结果必定取决于 b,因此返回 b。
因此,
a = True
print a and 'a=T' or 'a=F'
因为a = True,后面为 and,所以取决于后面,因为'a=T' 不是空字符串,所以 也为 True,后面是or,所以取决于当前,因此输出:
a=T
2.5 空值
用 None 表示,并不是 0,因为 0 是有意义的。
3.变量
3.1 变量名
变量名必须是大小写英文、数字和下划线(_)的组合,且不能用数字开头。
3.2 动态语言
python的变量本身类型不固定,因此称 python 为动态语言。
例如:
a = 123
print a
a = 'hello world'
print a
123
hello world
定义 a 时无需指定 a 的类型,可通过赋值自动判断,当 a = 123 时 a 是整型,当 a = 'hello world' 时 a 是字符串类型,成为动态语言。
3.2 具体分析
a = 123
b = a
a = 'abc'
print b
123

最开始 a 和 b 都指向了内存中的 123 。
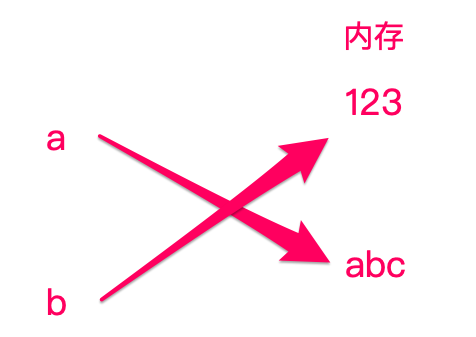
接着让 a 指向 'abc',而 b 仍指向 123 。
4.list / tuple 类型
4.1 list
4.1.1 构造
list(列表) 是 python 的内置类型,使用方法也很简单。
L = ['hello', 'and', 'python']
print L
['hello', 'and', 'python']
list 中的元素类型也不要求一样。
L = ['hello', 100, 'python']
print L
['hello', 100, 'python']
也可定义一个空list:
empty_list = []
4.1.2 使用
若要指定使用的元素:
L = ['hello', 100, 'python']
print L[0]
print L[1]
print L[2]
hello
100
python
注意:使用时不要越界。
list 还可以倒序输出:
L = ['hello', 100, 'python']
print L[-1]
print L[-2]
print L[-3]
python
100
hello
4.1.3 添加新元素
使用 append()或 insert()方法添加新元素。用法也很简单:
L = ['hello', 100, 'python']
L.append(200)
print L
L.insert(1, 'world')
print L
['hello', 100, 'python', 200]
['hello', 'world', 100, 'python', 200]
4.1.4 删除元素
使用pop()方法删除元素。若该方法不传参,则默认删除最后一个元素,否则删除指定位置的元素。用法:
L = ['hello', 100, 'python', 'hehe', 200]
L.pop()
print L
L.pop(2)
print L
['hello', 100, 'python', 'hehe']
['hello', 100, 'hehe']
4.1.5 替换元素
与数组类似:
L = ['hello', 100, 'python', 'hehe', 200]
L[2] = 'sss'
print L
L[-2] = 'haha'
print L
['hello', 100, 'sss', 'hehe', 200]
['hello', 100, 'sss', 'haha', 200]
4.2 tuple
4.2.1 构造
tuple(元组)与 list 非常类似,但 tuple 一旦创建完,就不能修改。
tuple 用()来括起来:
T = ('hello', 100, 'python', 'hehe', 200)
print T
此时,T 不能再修改。但可以访问,访问方法与 list 一样。
4.2.2 单元素的tuple
python 规定若 tuple 只有一个元素时,需要在第一个元素后面加上逗号:
T = ('hello', )
print T
(hello)
否则输出 hello而不是(hello)。
因为,若是不加逗号,python 解释器认为括号表示运算时的优先级,因此避免歧义,需要加一个逗号。
4.2.3 可变tuple
T = ('hello', 100, ['aaa', 'bbb'])
L = T[2]
L[0] = 'xxx'
print T
('hello', 100, ['xxx', 'bbb'])
可以发现,通过修改 L,改变了 T。
原因是,tuple 的不可变性,体现在指向不变上。
具体分析如下:
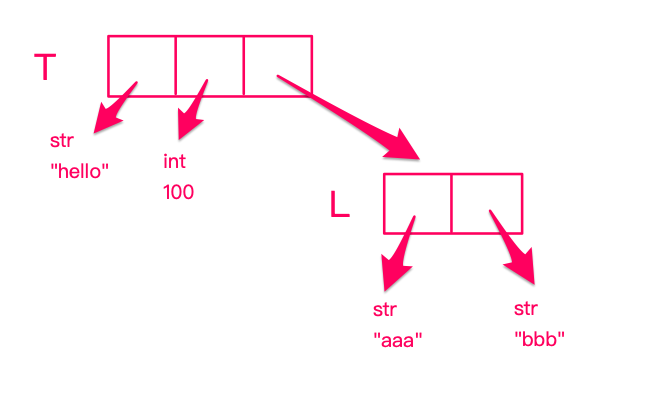
因此,当执行L = T[2], L[0] = 'xxx'时,L[0] 的指向发生了改变,但 T[2] 的指向仍然是指向 L,并未改变。若要创建一个无法改变的 tuple,则需 tuple 的每个元素都不可变。
5.条件判断与循环
5.1 if
用法很简单:
if 10 > 9:
print 'yes'
yes
if 后面还可加 not:
if not 9 > 10:
print 'no'
no
在 : 后面,代表代码块的开始。
5.2 if-else
用法如下:
if 11 > 10:
print 'yes'
else:
print 'no'
yes
注意:else后面有:。
5.3 if-elif-else
用法如下:
age = 3
if age >= 18:
print 'adult'
elif age >= 6:
print 'teenager'
elif age >= 3:
print 'kid'
else:
print 'baby'
kid
注意,每个判断语句后面都有 :。
5.4 for循环
用法如下:
L = ['hello', 'why', 'yes']
for str in L:
print str
hello
why
yes
str 变量是在 for 循环中定义的,意思是依次取出 list 中的每一个元素,赋值给 str ,然后执行缩进中的内容。
注意:for 后面有L :,且 for 与 in 搭配。
5.5 while循环
格式如下:
a = 1
while a < 5:
print a
a += 1
1
2
3
4
注意 while 语句后面的 :。
5.6 break与continue
5.6.1 break
a = 1
while True:
print a
a += 1
if a > 5:
break
用法与c/c++类似。
5.6.2 continue
用法与c/c++类似。这里不具体举例。
5.7 多重循环
6 dict 和 set 类型
6.1 dict
6.1.1 构造
感觉类似于C++的map。是将两个类型对应起来。
简单地说,list 与 tuple 中每个元素的类型都是一个已知类型,而 dict 中每个元素的类型都是一个映射(键值对key-value)。
例如,我们想将一个班的每个同学的姓名与他的成绩存储下来,且需一一对应,那么用 dict ,可完成这个任务。因为 dict 中的每个元素,可以存储一个姓名与成绩的映射。用法如下:
d = {
'Amon': 90,
'Kiki': 95,
'Jack': 80
}
print d
print len(d)
{'Kiki': 95, 'Amon': 90, 'Jack': 80}
3
6.1.2 使用
d[key] = value,如下:
d = {
'Amon': 90,
'Kiki': 95,
'Jack': 80
}
print d['Amon']
若 d 中没有你的 key,就会报错:
d = {
'Amon': 90,
'Kiki': 95,
'Jack': 80
}
print d['Tina']
报错提示:
Traceback (most recent call last):
File "hello.py", line 6, in <module>
print d['Tina']
KeyError: 'Tina'
因此,有个函数可以判断 dict 中是否含有某个 key:
if 'Tina' in d:
print d['Tina']
或者使用:
print d.get('Tina')
若没有所需的key,输出 None,否则输出 value。
这样就不会报错。
6.1.3 dict的特点
1.key 不能重复,且 key 不能变(所以 list 不能作为key)
2.在 dict 中,元素是没有顺序的(所以不能用d[0], d[1]...)
3.查找速度快,但占用内存大
6.1.4 更新dict
添加新元素:
d = {
'Amon': 90,
'Kiki': 95,
'Jack': 80
}
d['newPerson'] = 60
print d
{'newPerson': 60, 'Kiki': 95, 'Amon': 90, 'Jack': 80}
6.1.5 遍历dict
与遍历 list 类似:
d = {
'Amon': 90,
'Kiki': 95,
'Jack': 80
}
for key in d:
print key, d[key]
Kiki 95
Amon 90
Jack 80
6.2 set
6.2.1 构造
set 与 dict 的区别的,dict 中存的是一个 key-value 的键值对,而 set 中只有 key。
set 中的 key 也不能重复,相当于 set 是一个不能有重复元素的集合,且元素无序。
set 的调用方法是调用他的构造函数 set(),在里面传入一个 list,list 中存的是需要传入的 key,用法如下:
s = set(['Amon', 'Kiki', 'Tina'])
print s
set(['Kiki', 'Amon', 'Tina'])
当 set 中有重复元素时,会自动去重。
6.2.2 使用
由于 set 无序,所以我们无法通过 s[0]、s[1].. 这样的方式来调用,但可以判断某个元素是否在 set 内:
s = set(['Amon', 'Kiki', 'Tina'])
print 'kkk' in s
False
6.2.3 set 的特点
1.元素不能重复,且不可变(所以 list 不能作为 set 的元素)
2.在 set 中,元素没有顺序(所以不能用 s[0],s[1]...)
3.判断某个元素是否在 set 中的速度很快
6.2.4 遍历 set
与 list 的遍历类似:
s = set(['Amon', 'Kiki', 'Tina'])
for name in s:
print name
Kiki
Amon
Tina
6.2.5 更新 set
添加新元素:add()
删除元素:remove()
(若删除元素不存在,会报错)
如下:
s = set(['Amon', 'Kiki', 'Tina'])
s.add(100)
print s
s.remove('Amon')
print s
set([100, 'Kiki', 'Amon', 'Tina'])
set([100, 'Kiki', 'Tina'])
7.函数
7.1 python内置函数
python 的官方文档:
http://docs.python.org/2/library/functions.html#abs
若要查看某个函数的用法,也可以:
print help(abs)
Help on built-in function abs in module __builtin__:
abs(...)
abs(number) -> number
Return the absolute value of the argument.
7.2 编写函数
定义函数使用 def语句,依次写出函数名、括号、括号中的参数和冒号,例如:
def my_abs(x):
if x >= 0:
return x
else:
return -x
a = -3
print my_abs(a)
3
若没有返回语句,则返回 None(return None),简写为return。
他的用法用法与C/C++差不多,也可以递归调用自身。
7.3 返回多值
用法如下:
def my_abs(x1, x2, x3):
return abs(x1), abs(x2), abs(x3)
a = -3
b = 2
c = -5
print my_abs(a, b, c)
(3, 2, 5)
返回值是一个 tuple。
7.4 默认参数
和C++的默认参数差不多。
def sum(x1, x2, x3 = 0, x4 = 0):
return x1 + x2 + x3 + x4
a = -3
b = 2
print sum(a, b)
-1
7.5 可变参数
用法如下:
def sum(*args):
ans = 0
for em in args:
ans += em
return ans
print sum(2, 3, -6)
-1
在参数前加 *,代表这是一个可变参数,相当于是一个 tuple。
和C/C++的可变参数略有不同。
8.切片
8.1 切片简述
若想遍历一个 list 的前 n 个元素,可这样做:
L = [4, 26, 8, 2, 11, 33, 27]
for i in range(5):
print L[i]
4
26
8
2
11
range(n) 代表 0~(n-1)之间的数,让 i 等于这些数,再调用 L[i]。
而 python 中的切片操作能达到相同的效果:
L = [4, 26, 8, 2, 11, 33, 27]
print L[0:5]
[4, 26, 8, 2, 11]
[a, b] 是一个前闭后开的区间,代表第 a 个元素到第 b 个元素,但不包括第 b 个。
[:]代表所有元素。
[::a]代表每 a 个元素取一个元素。
L = [4, 26, 8, 2, 11, 33, 27]
print L[::2]
[4, 8, 11, 27]
同样,对 tuple 也可切片。
8.2 倒序切片
python 支持 L[-1] 取最后一个元素,同样也支持 L[-1:] 倒数切片:
L = [4, 26, 8, 2, 11, 33, 27]
print L[-3:]
print L[:-3]
print L[-5:-2]
print L[-6:-2:2]
[11, 33, 27] (倒数三个数)
[4, 26, 8, 2] (第一个数到倒数第三个数(不包括))
[8, 2, 11](倒数第五个数到倒数第三个数(不包括))
[26, 2](每2个中1个,倒数第六个数到倒数第二个数(不包括))
8.3 字符串切片
字符串和 Unicode 也可以看做是一种 list,每个字符是一个元素。如下:
print 'hello world'[2:7]
llo w
9.迭代
9.1 迭代的概念
在python中,迭代就是指 for 循环。for 循环可以作用在有序或无序集合上。
9.2 索引迭代
Python中,迭代永远是取出元素本身,而非元素的索引(下标)。
若需要元素的索引,可使用 enumerate() 函数,他将一个集合变成了每个元素为 tuple 的集合。如下:
L = ['Amon', 'Kiki', 'Tina']
=> L = [(0, 'Amon'), (1, 'Kiki'), (2, 'Tina')]
再对他进行迭代:
L = ['Amon', 'Kiki', 'Tina']
for i, name in enumerate(L):
print i, name
0 Amon
1 Kiki
2 Tina
9.3 迭代dict
dict 在 for 循环中,每次可以取出他的一个 key。若我们想迭代 value ,可用 values() 方法。
d = {
'Amon': 90,
'Tina': 60,
'Kiki': 80
}
print d.values()
for grade in d.values():
print grade
[80, 90, 60]
80
90
60
values() 方法实际上将 dict 转化为一个包含 values 的 list。
除了 values() 方法,python 中还提供了 itervalues() 方法:
d = {
'Amon': 90,
'Tina': 60,
'Kiki': 80
}
print d.itervalues()
for grade in d.itervalues():
print grade
<dictionary-valueiterator object at 0x102930730>
80
90
60
itervalues() 方法不会将 dict 转换,而是在每次迭代过程中,取出 value,所以更节约内存。
除此之外,我们还可以使用 items() 方法同时迭代 key 和 value,items() 方法将 dict 对象转换成了包含 tuple 的 list。
d = {
'Amon': 90,
'Tina': 60,
'Kiki': 80
}
print d.items()
[('Kiki', 80), ('Amon', 90), ('Tina', 60)]
所以,对 d.items() 进行迭代,即可得到 key 和 value:
d = {
'Amon': 90,
'Tina': 60,
'Kiki': 80
}
for key, value in d.items():
print key, ':', value
Kiki : 80
Amon : 90
Tina : 60
10.列表生成式
10.1 简述
当我们想将一个 list 中的元素设置为 11,22,33 ... 1010,若是一个个的赋值,过于复杂,可用列表生成式用一行搞定:
L = [x * x for x in range(1, 11)]
print L
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
但若是我们只要 x 为偶数的情况呢?可在列表生成式中加入条件判断:
L = [x * x for x in range(1, 11) if (x % 2 == 0)]
print L
[4, 16, 36, 64, 100]
10.2 多层嵌套
如下:
print [a + str(b) for a in 'avsde' for b in range(1, 3)]
['a1', 'a2', 'v1', 'v2', 's1', 's2', 'd1', 'd2', 'e1', 'e2']
参考
https://www.imooc.com/learn/177